


Introduction
Welcome! In the upcoming series of articles (this is Part 1), I’ll be discussing some things to consider if you want to use Kubernetes to host an application that is subject to PCI DSS. I have been interested in containers for quite a while now and have recently had a lot of PCI DSS clients asking about Kubernetes. The concepts and controls in PCI DSS don't always translate well to a containerized environment which gave me the idea to write this series. The series will be split up into PCI DSS domains and I'll do my best to provide some discussion topics as well as demonstrations for each. Nothing in this series is a guarantee that you'll be compliant with PCI DSS; there are too many variables to consider. My hope is that this provides a good starting point for planning a migration onto Kubernetes.
This series assumes that you have a solid understanding of Kubernetes operation and know how to get a cluster up and running and deploy applications on it. This is not intended to be an introduction to getting Kubernetes up and running, there are plenty of resources online for that. This series will cover more specific Day 2 operations topics.
As a last note, most of the topics will apply to any Kubernetes cluster whether it’s a self-hosted or a managed Kubernetes service like Amazon Elastic Container Service for Kubernetes (EKS), Azure Kubernetes Service (AKS), or Google Kubernetes Engine (GKE). Even in the case of a managed service, Amazon or Google will maintain compliance up to the node level, which are the virtual servers that host the Kubernetes components, but anything that is configurable within Kubernetes itself will NOT be covered under their PCI Attestation of Compliance (AOC) and is your responsibility to maintain.
I'll mostly try keep this series in the order of the PCI DSS, so first up is network architecture and firewalls which corresponds with PCI DSS requirement 1. As it applies to Kubernetes, here are the high-level controls that need to be met:
1. Maintain a current network diagram.
2. Segment publicly accessible and internal components (DMZ).
3. Restrict inbound and outbound traffic.
I’ll cover each one of these in more detail below.
A Note on Node Firewalls
I’ll mostly focus on Kubernetes-level networking but if you are hosting your own cluster you need to think about network firewalling for your nodes. Kubernetes requires only a few well-defined ports in order to function:
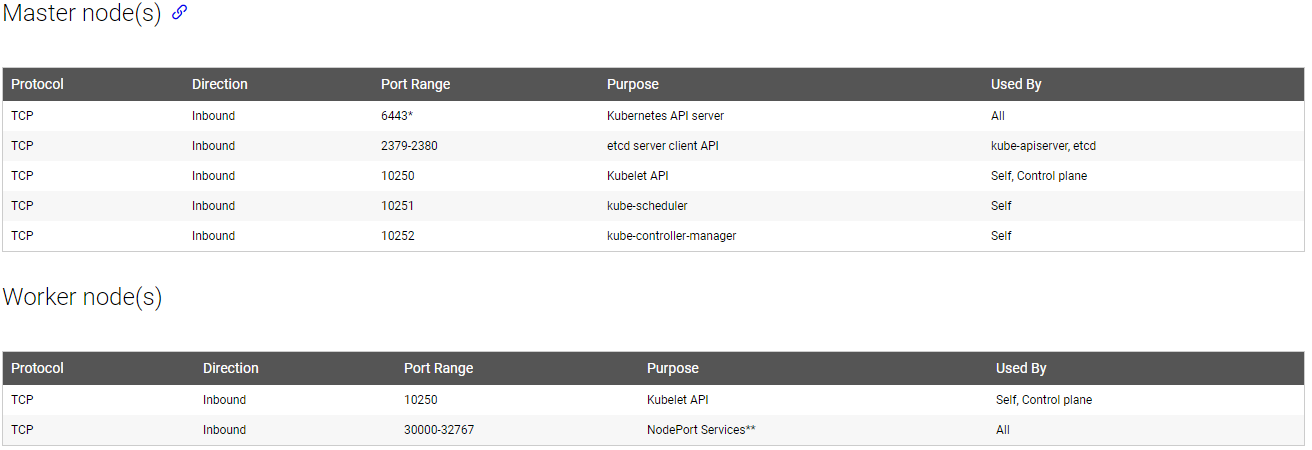
https://kubernetes.io/docs/setup/independent/install-kubeadm/
TCP 6443 is the default port used by kubectl to run commands on the cluster. You should consider locking that port to specific jump server(s) to help reduce your scope.
Maintain a current network diagram
You are always going to need to maintain a Kubernetes component diagram. So far, the best solution I’ve found is the Kubernetes Deployment Language (KDL) which is described here: : https://blog.openshift.com/kdl-notation-kubernetes-app-deploy/. Because of the nature of how Kubernetes schedules and deploys pods, it will be next to impossible to keep an up-to-date diagram showing pod IP addresses and which worker nodes they reside on. Since the whole point of Kubernetes is to abstract that all away, it makes more since to keep high-level data-flow and conceptual diagrams instead. The high-level diagrams need to show the Kubernetes API objects (pods, services, ingresses, configmaps, secrets, persistent volumes, etc.) that make up your application and the traffic flows allowed between those components. While for some PCI DSS assessors, this will be enough to check the compliance box, you really should have some tool to monitor (and optionally visualize) connections between pods, services, ingresses, etc. in real-time. As far as I know this is not something built into Kubernetes, so you’ll need additional tooling. There are a lot of free and commercial tools that can accomplish this for you. I’ll discuss a few below.
WeaveScope
If you are using Weave as your container network interface (CNI) then you can deploy WeaveScope which runs as a daemon-set on each of your nodes and provides a web application to view your component status. a real-time visualization of your cluster components.

FYI: I use this repository which generates kubectl aliases to make typing out commands easier: https://github.com/ahmetb/kubectl-aliases
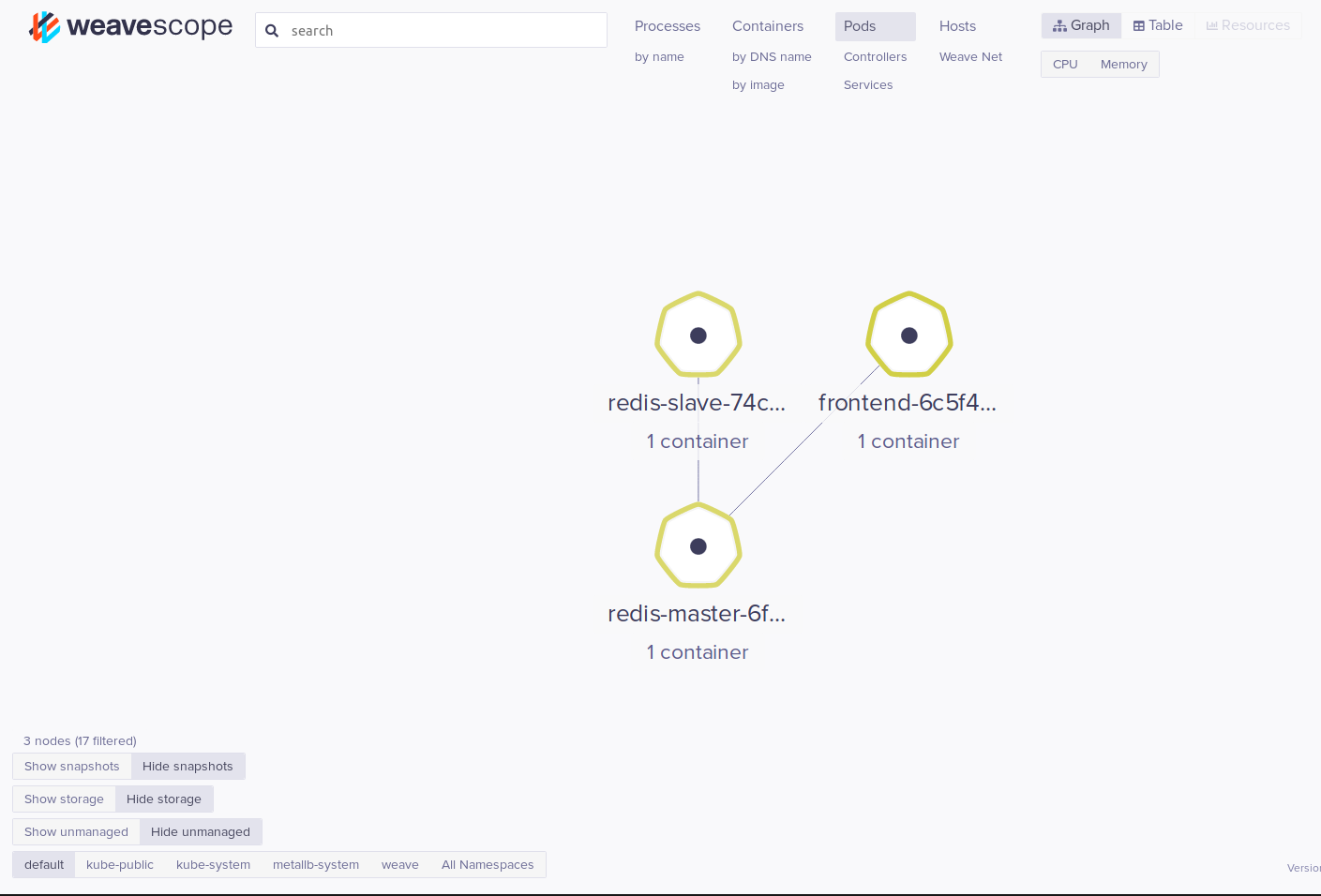
Here is an example of a WeaveScope visualization:
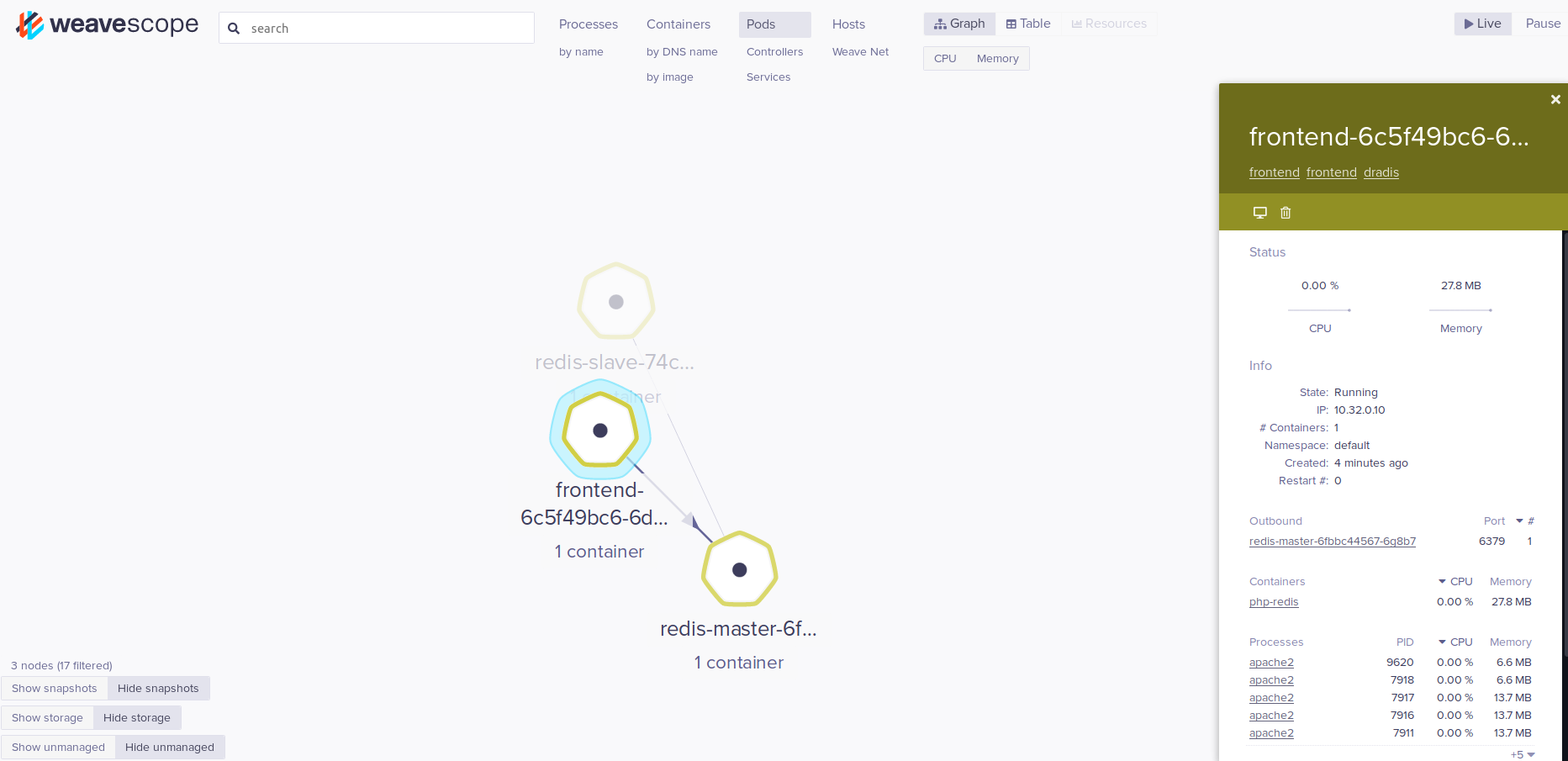
I can also drill into pods and view resource usage and network connection information. In this example I can see that my frontend pod is talking over port 6379 to a Redis master. This can be useful for drafting network policies which I’ll discuss shortly.
Istio
Istio provides a service-mesh for microservice communication. Istio can augment layer 3-4 Network Policy rules with layer 7 firewalling. It can also provide network metrics, intra-pod encryption, authentication, and authorization. I like this tool because it gives you more options in choosing a CNI and it can run as a sidecar. That means if you enable sidecar injection in a namespace, then any pod you create will get an Istio proxy pod created automatically that manages all inbound and outbound network traffic. This is great for developers and operations personnel because it requires only minimal changes to your pod manifests and no changes at all to your application code. Istio does not come with any visualization tools out of the box but there are third party tools like Vistio (https://github.com/nmnellis/vistio) which can provide it.
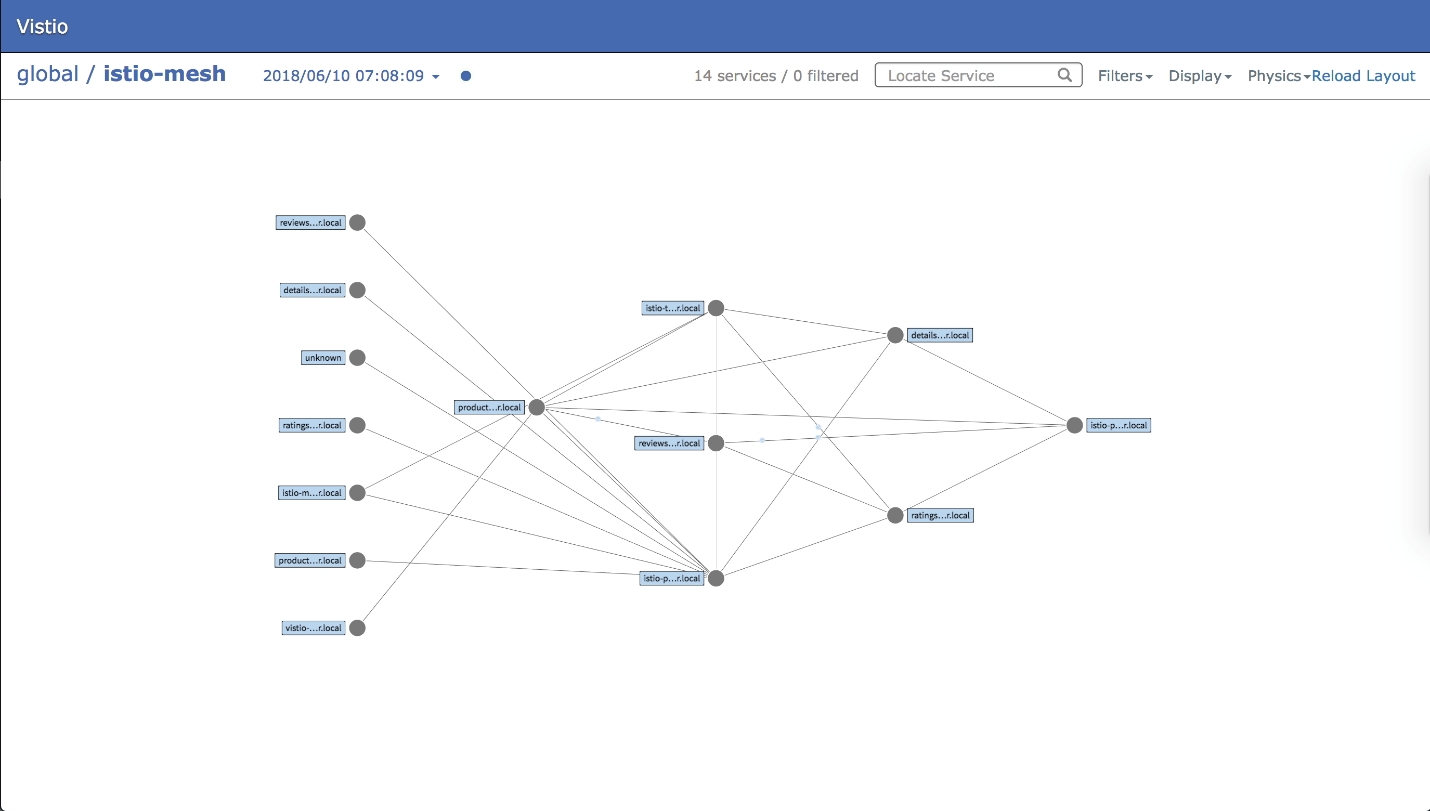
https://github.com/nmnellis/vistio/blob/master/documentation/sample.png
Segment publicly accessible and internal components (DMZ)
The PCI DSS network architecture controls require that you place publicly accessible services on a DMZ network segment and other sensitive components on internal private subnets.
These controls don’t translate well to Kubernetes architecture. When bootstrapping a Kubernetes cluster, you define a single (but big, /8 or /16 typically) RFC 1918 address pool that is used by all the pods in the cluster. There is no way to meet the controls as written. It is possible to meet the intent of the requirements with Kubernetes. There are two ways you can create a “DMZ”. The first is by creating a Kubernetes Service object and designating it either a LoadBalancer or a NodeIP. You can also assign a Kubernetes Ingress object. Either of these methods will expose your pods outside of the cluster (and depending on the architecture of your node network, the Internet). If you don’t want your service to be accessible, then you just assign it a ClusterIP which is only accessible within the cluster itself. In my example, I have my frontend service assigned to a LoadBalancer and it has an external IP address assigned. My Redis services only have ClusterIPs so cannot be accessed from outside the cluster.

So rather than have a DMZ and internal network segment, in Kubernetes, you just expose a service for a front-end application and use ClusterIPs for internal applications, and then use Network Policies to permit or deny specific traffic. It’s not quite how the frameworks are written but it definitely meets the intent of the requirements.
Restrict inbound and outbound traffic
The network firewall protecting your nodes is not enough to protect a PCI application on Kubernetes. Traffic between pods may happen on a single server. If traffic never leaves the node then a network firewall is not going to help at all. Kubernetes has a native Network Policy resource (https://kubernetes.io/docs/concepts/services-networking/network-policies/) which can isolate pods and filter traffic. With Network Policies, you can filter ingress and egress traffic based on namespaces, labels, or IP address, and allow or deny specific ports. By default, pods accept traffic from any source. But as soon as a Network Policy is assigned, they switch to a default-deny policy and only allow the traffic you whitelist.
An important note to remember here is at the Pod and Service manifest levels, you need to specify exposed ports in order for them to be accessible at all. Use the spec options to do this, for example in my Redis service:

And the Pod manifest:
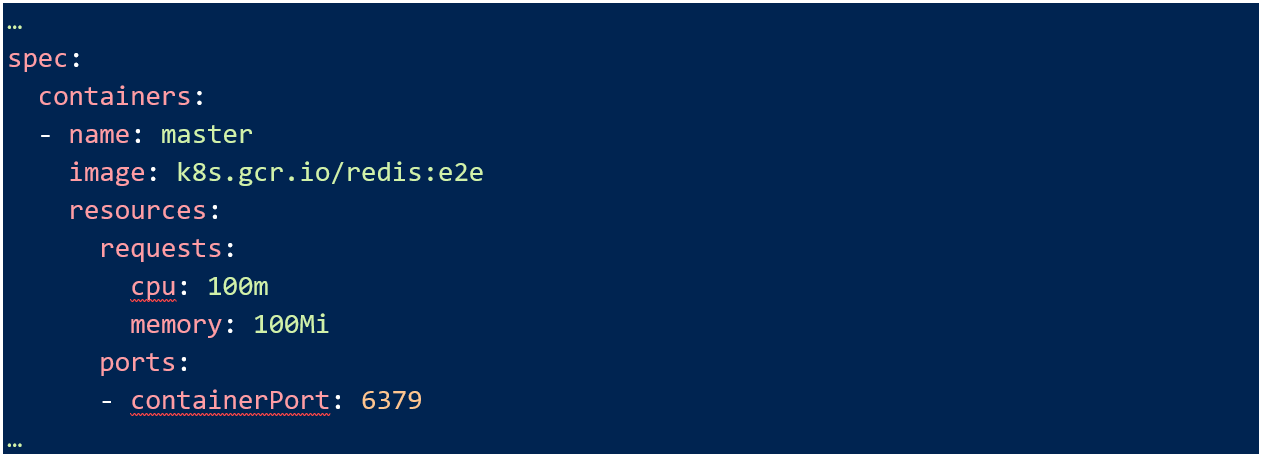
PCI DSS also has a soft requirement to segment off any applications you don’t want included in an assessment. I say soft requirement because you could have all your applications and network in scope if you want but that greatly increases the chance of missing a control somewhere and not meeting your compliance obligations.
The most flexible way to assign Network Policies is by using labels on your Kubernetes objects. You can’t rely on IP addresses, and you won’t always have a namespace per application, but you can assign and rely on object labels. You can use any number of arbitrary labels that you want. In my example I am using an application name and tier to provide granularity when creating Network Policies. For example, if I have a PCI application and non-PCI application residing in the same cluster, I could use labels like this:
Non-PCI application:

PCI application:

Anyone familiar with configuring traditional network firewalls should have no problem creating Kubernetes Network Policies. They are functionally identical, they just operate within different scopes and use YAML instead of Cisco or Juniper CLI commands.
Demonstration
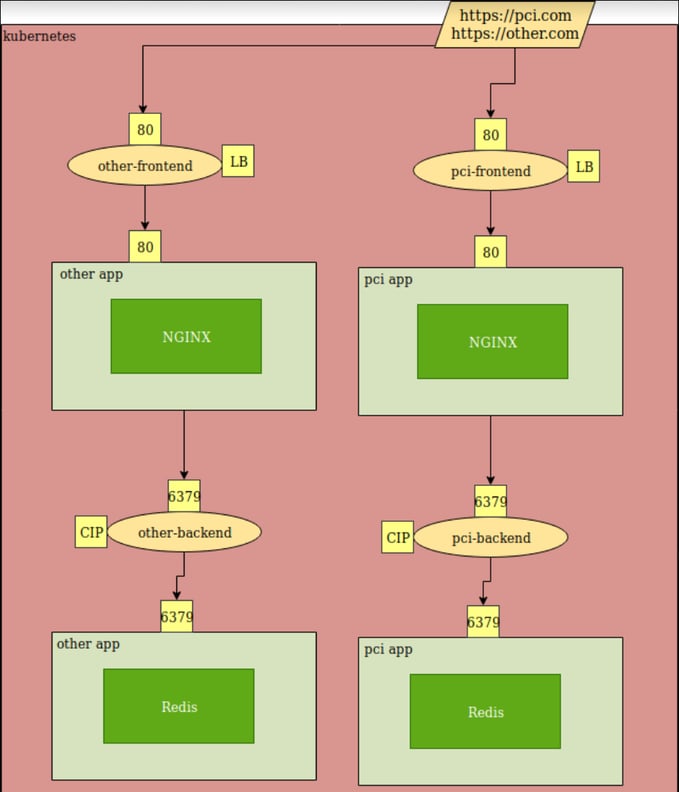
Here is an example using the concepts from above. For simplicity’s sake, I am running two identical applications. One that is in-scope for PCI and another that is not. The goals of this demonstration are:
- Allow external/public connections only to the pci-frontend service.
- Deny all network access between the “pci” and “other” application.
- Restrict traffic between my front-end and back-end pods to only TCP 6379.
- Deny all egress traffic.
If you want to try it yourself, you can re-create this environment by running kubectl create -f https://gist.githubusercontent.com/pdorczuk/7d1d3125a93897bd88ffab517bf33a9a/raw/ca4c1a6f8f2e17451be446d555989e37fc8d6d9c/example-all.yaml
Here are my pods and services:
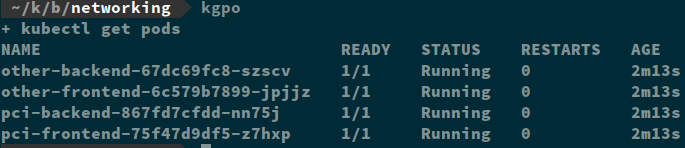

I’ve already met goal # 1 which is to limit publicly accessible services. You can see from the manifest and running services that only my “*-frontend” services have external IP addresses assigned and are accessible outside of the cluster.
Within the cluster, there is no network separation between my applications. If I shell into my “other” application pods, I can access my “pci” application.

Remember that when you apply any network policy to a pod, it immediately switches to a default deny. The first thing that always needs to do be applied is a blanket deny-all policy to every pod in my cluster.
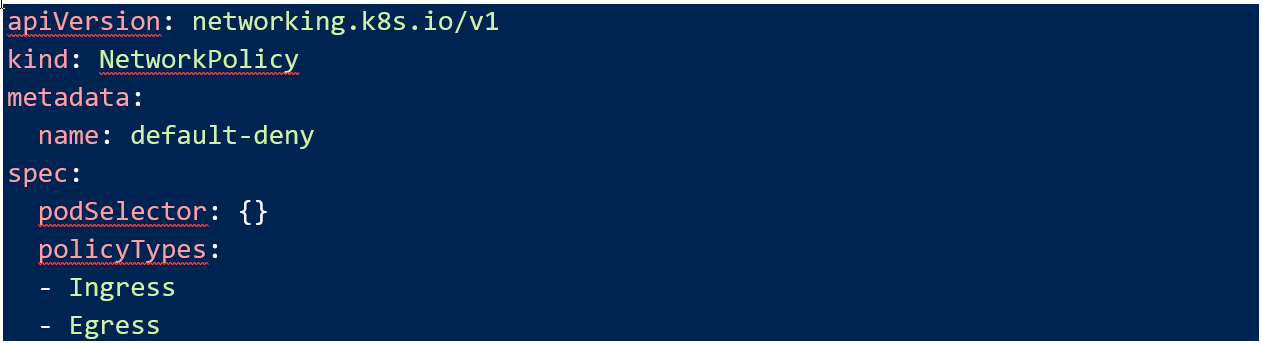
Note that the pod selector is empty which means it will apply to all my pods. I have also marked it as an Ingress and Egress rule, so no traffic is permitted. Now my “pci” and “other” applications are segmented.
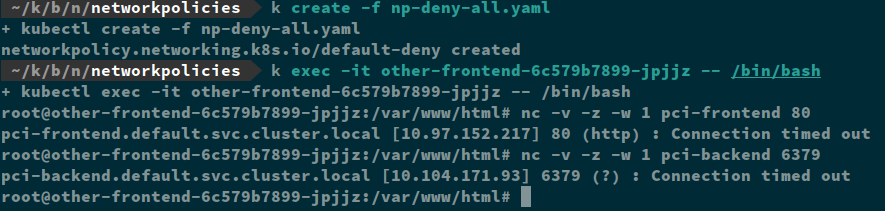
So, with that one policy, I have accomplished two goals, I have segmented my applications from each other and prevented all egress traffic.
The last step then is to allow the traffic that my “pci” application needs to function. Using the labels specified in my manifest, this Network Policy will allow traffic from the “pci-frontend” to the “pci-backend”
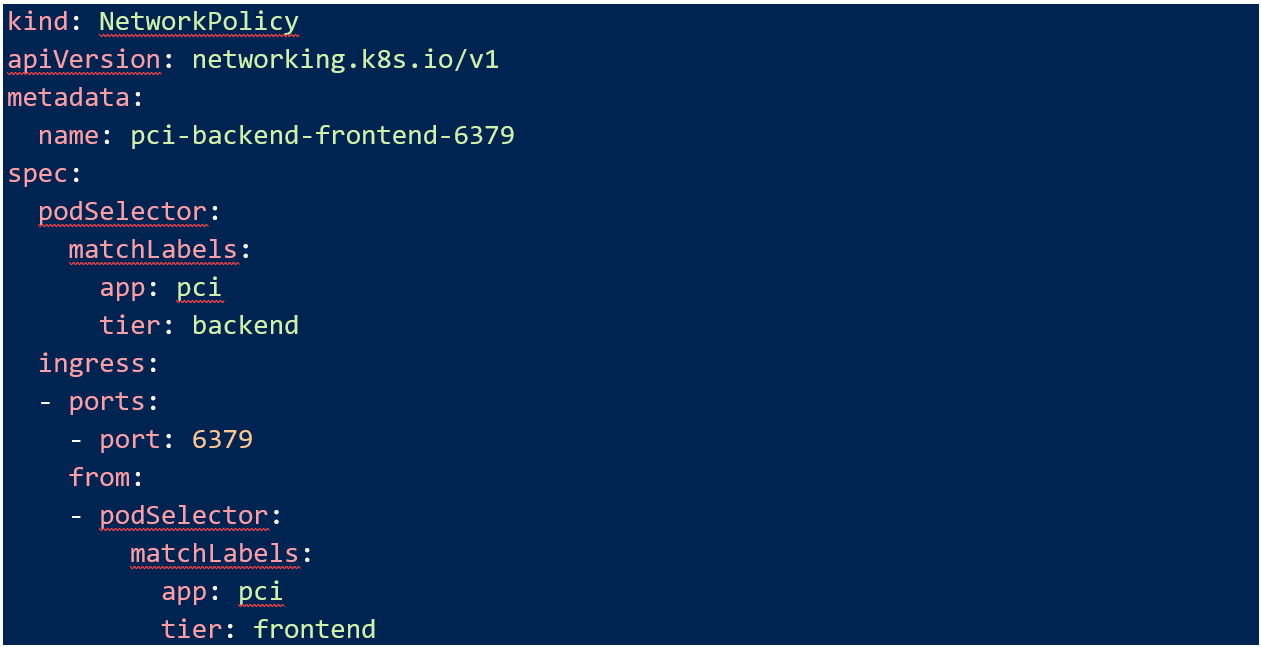
Now that this is applied, my “pci-frontend” pod can talk to my “pci-backend” pod over port 6379.

And my “otherapp” is still denied.

The last step is to allow TCP port 80 into my “pci-frontend”. In my example, the pod network is 10.96.0.0/12 so I allow port 80 from everywhere except that. Your situation might be different, you could allow this over a cloud or network load balancer for instance.
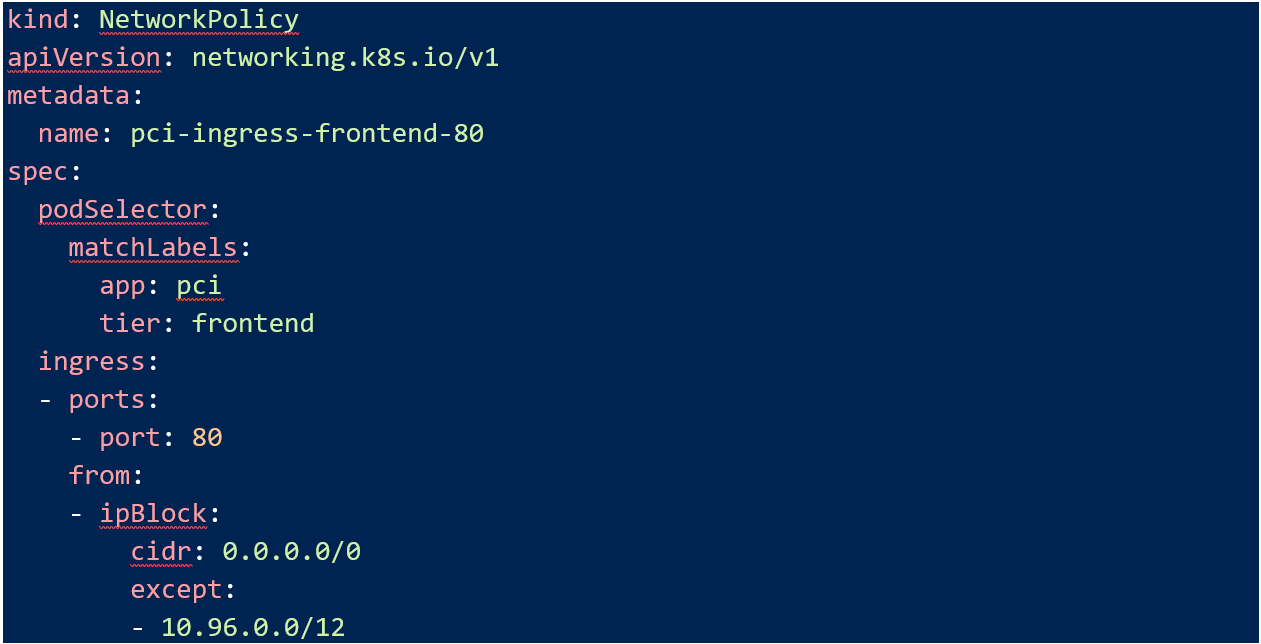
Conclusion
Hopefully this helps get some brainstorming started when planning a Kubernetes deployment. While Kubernetes may make life easier for developers, it is another layer to think about when architecting applications. PCI DSS most definitely was not written with cutting-edge platforms like Kubernetes in mind. While it may be difficult or impossible to meet the controls verbatim, it is certainly possible to meet the intent of the controls. Make sure you start thinking about your compliance controls early on in the planning process and work with your QSA to identify any control gaps.