



For any penetration testing engagement, internet-facing services are an important part, and as every environment is different, there are multiple ways to obtain valuable information about these services before determining if they are vulnerable to exploitation. Even given the different approaches and tools available for such assessments, this type of engagement usually always begins with passive reconnaissance, which relies on information that can be obtained without direct interaction with the services. Some examples of these non-invasive techniques include using Google dorks, engaging online tools like Shodan or SecurityTrails, or even looking up a company’s public GitHub repositories.
However, in most cases, passive reconnaissance will only scratch the surface, particularly if the results of a passive scan are compared with the amount of information that can be obtained during the second phase which is active scanning, where the target system is purposefully engaged and exploitable services are sought. Similarly, multiple tools can be used for this task—some of which have the ability to keep track of network packets and alert testers if something goes wrong, while others just focus on speed.
This versatility in tools is important when assessors are attempting to test, as they need to be able to work with unique environments every time. Different organizations structure their security differently, and their configurations are important because they directly impact the result of these reconnaissance scans. For instance, an organization may configure an access control list (ACL) for its external services—ACLs can be anything from using “iptables” for an individual Linux host to security groups from a cloud provider like Amazon or Azure. Also included are web application firewalls (WAF) that could have some advance features to prevent unwanted traffic from reaching web applications. Assessors can encounter a firewall that was set up to block most open ports but has no rate limiting and will allow any number of packets without any restriction. Alternatively, the system may be configured to drop all packets if too many have been received in a specific amount of time—an oft-used security strategy usually designed to prevent denial of service (DoS) or limit port scanning.
For Schellman, our approach depends on the results of said reconnaissance, as well as the final goal of the test. In some cases, we just want to know if a service like SSH is open on any host within a large network, and if so, then we need speed more than reliability from the tools used. Conversely, reliability will be a priority if we want to know specific information, such as what version of the SSH service is enabled on each host. However, whatever the goal, it’s not truly possible to anticipate a target system’s behavior before actually conducting our testing—thanks to each client’s unique setup—so an initial round of active scanning is usually performed, after which a second scan can be launched with specific parameters that will account for defenses that were identified in the initial probe.
Let us see how these two approaches look from a firewall standpoint:
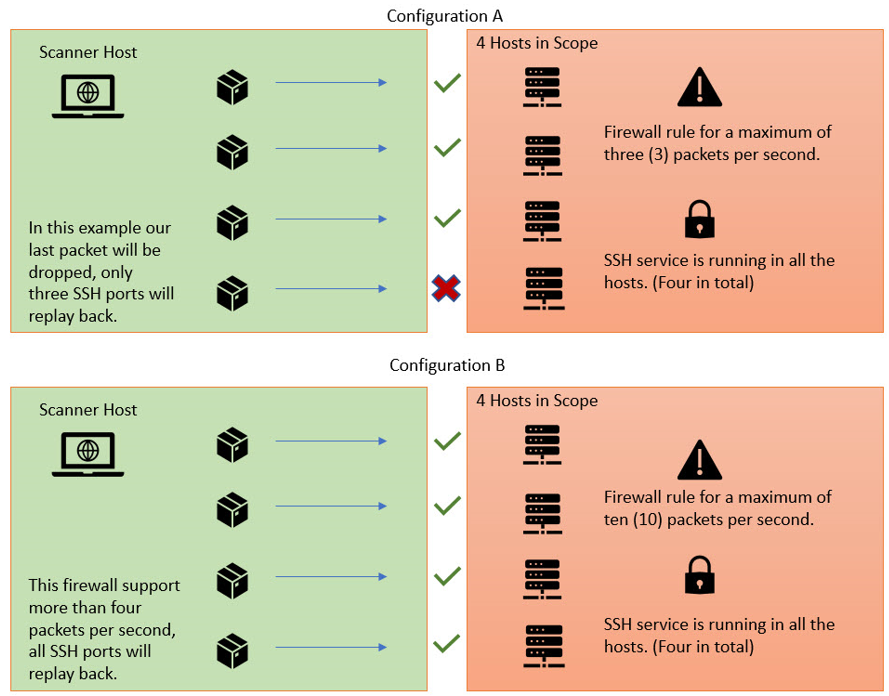
In the previous example, we noted that the firewall with configuration ‘A’ will drop our packets if we send more than three packages per second, compared with the configuration ‘B’, that will allow up to ten packets per second. However, how we can know which behavior to expect before we conduct our testing? Unfortunately, we often will not know until an initial round of active scanning is performed. Once this behavior has been identified with an initial scan, a second scan can be launched with parameters that will account for these defenses.
Let us analyze our first scenario in which we want to determine all services that are listening on a network range. For this task, we’ll need a tool with the ability to track individual packets and alert us of any traffic fluctuation between our host and the target systems. Nmap is a good example and has been actively supported for many years, although it is not the fastest network scanner when compared with other tools like Masscan. Even with the best setup, it can take hundreds of hours to complete a full (all 65,535) TCP port scan of an enterprise network that contains thousands of hosts. But for this scenario, we are looking for reliability—not speed—and that is something that Nmap can help us to achieve.
Let’s visualize how Nmap alerts us when it detects that not all the packets are reaching their destination during its initial scan.
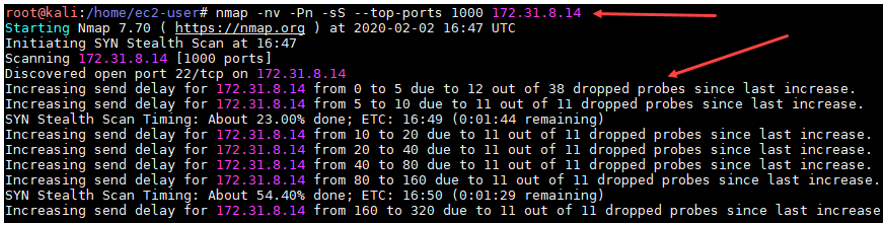
As we can observe, Nmap is trying to let us know that our packets are being dropped by the firewall while simultaneously is trying to automatically adjust the number of packets per second that are being sent. Despite these adjustments, it doesn’t guarantee that the firewall is going to change its behavior and let our packets go through. Plus, the packets that were dropped will never reach their destination and will not return any useful information on the state (open/closed/filtered) of the port. At this point, we can stop our initial scan and launch a second one with a new, more customized setup that will hopefully avoid packets getting dropped.
It is important to mention that Nmap is not the only tool on the market that can help us determine if there is abnormal network behavior between us and our target. There are other tools that can detect network congestion or packets getting dropped, like Nessus. We can also create our own tools or scripts, keeping in mind that the tool needs the ability to track the packets and alert us if they are dropped before reaching their destination.
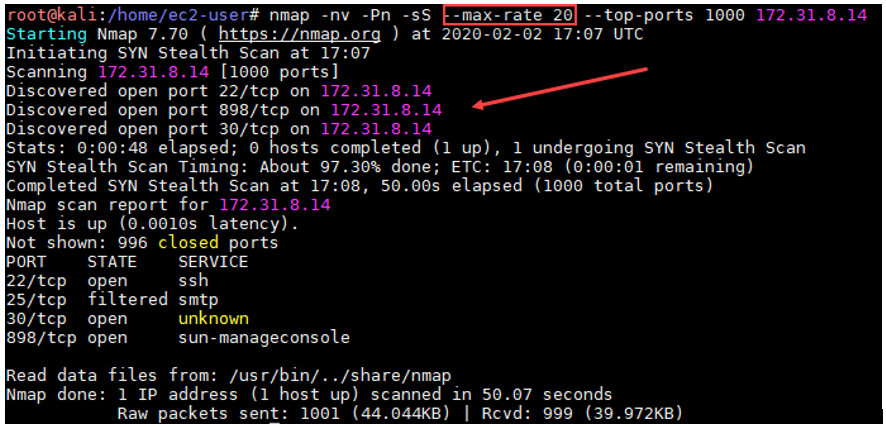
Noted in the above screenshot, we’ve added a new parameter that limits the second Nmap scan to a maximum of twenty packets per second. Now, all packets are reaching their destination without any issues and the scan is returning useful data about the open ports. While this solution works for limited scans, if we are planning to scan all 65,535 ports for each host in a large environment, it may take several days depending on the size of the network range. To accommodate as such, there are some workarounds, such as splitting our scan into small groups and prioritizing the most important ports. Such specialization does provide some advantage, as some results become available to work with more quickly than they would during a single, large scan that took multiple days.
Let's review our second example with a firewall setup that supports a thousand packets per second, in this scenario, the goal is to find if there are any hosts with the SSH service open, and to do so, we can use a tool like “Masscan” as we don’t really need to know if the service is open for every host. Masscan gives us the ability to scan thousands of hosts and services in just seconds, but follows a stateless approach, meaning that it is not going to tell us if the packets that we are sending are getting dropped. Still, for this example, our main goal is to obtain a quick result of any host that is running SSH service, even if we could be losing some packets by surpassing the firewall limits—it is important to keep in mind that fewer services will show up if we increase the number of packets per second that the scanner will send, but as previously mentioned, our goal was to just find any host with an SSH open port.
But the configuration of the firewall is not the only impediment that could affect the type of scan we execute during testing—there are many other possible constraints, such as the amount of bandwidth or how much traffic is impacting our target network at the time of our scans. These constraints are things that we cannot control and the reason why it is important to have a good grasp on the expected behavior of the target environment—hence why initial scans are so critical.
Fortunately, we’ve established that there are multiple tools to choose from after mapping of the system, and circumstances have been achieved. Directory brute-force scanners can also adjust the number of packets per second sent, and tools like Wfuzz have multiple parameters that control the time between packets or the number of packets that we send, allowing us to bypass some firewall restrictions. Using any of these as a first option is fine as well, but know that running these scanners as a part of an automatic enumeration process already in place for hundreds of web sites means likely missing a lot of directories, thereby forcing manual scans to first understand the behavior of the WAF before running the automatic process again with the new knowledge in hand.
When it comes to penetration testing, not all the environments will be the same, and there will always be something new to learn from each engagement, be it networking or web applications, with familiar tools or new techniques. What it all boils down to is the importance of embracing the versatility of the means available and the environment being tested. Unique configurations of a system are not much of an obstacle with the right tools, be they custom or established—just remember to tailor every approach to the completed reconnaissance, and always run some manual scans and compare the results with any automatic process that is in place, especially for massive networks where the automation is a must.